
Codename HeliTrack

Codename HeliTrack
Identifying and Tracking Ground Objects from Air to Improve Public Safety and Military Defense Capabilities (You can view the presentation online here. You can also go to the project’s GitHub repository for more technical details.)
Motivation
I got the inspiration for this project after I took a Machine Learning course through Coursera about a year ago. There I learned about the role Neural Networks play in Computer Vision and I wanted to do something similar ever since. Another source of inspiration for me was the idea of improving public safety and military defense. In the words of the retired NSA director, General Keith Alexander : “In recent years, … [government surveillance] programs, together with other intelligence, have protected the U.S. and our allies from terrorist threats across the globe … preventing the … potential terrorist events over 50 times since 9/11.”
The Challenge
The challenge for me became to create object identification and tracking computer vision prototype for advanced air-to-ground surveillance to improve military defense and public safety.
The Data: DARPA Neovision2
To achieve my objective I found a great dataset from DARPA and University of Southern California for their Computer Vision project called Neovision2. It is a set of human annotated frames from movie clips filmed from a helicopter flying over the Los Angeles area. The annotations include boxes capturing objects of interest and classifications of those objects. The dataset included several object classes such as:
- Car
- Truck
- Tractor-Trailer
- Bus
- Plane
- Helicopter
- Person
- Cyclist
The Model
In addition, for the choice of neural networks to work with, I decided to concentrate on two models:
- Faster Region-based Convolutional Neural Network or Faster R-CNN with Deep Residual Learning. It is a very Deep Neural Network with an intelligent region of interest proposal approach. I chose it due to seemingly being the golden middle in terms of speed and performance among the models I surveyed.
- Single Shot MultiBox Detector or SSD with MobileNets, which is a less accurate but a faster neural network. I chose these models to see if a more accurate but slower model such as Model 1 is suitable for my purposes, or if faster but less accurate model such as Model 2 can still be adequate. And I performed all my training and testing using Google’s Tensorflow.
Training Results
When I embarked on training my models I noticed right away that Model 1 converged much quicker than Model 2 did. Its total loss at training step 60,000, for example, was more than 10 times smaller than Model 2 total loss at that time. So I became hopeful that I have found the solution.
The Working Prototype
After extensive 2-day training, the air-to-ground computer vision system utilizing Model 1 was capable of
- Object detection among 10 classes.
- Object tracking.
As you can see from the sample video below (click on the thumbnail to play), the model is pretty good:
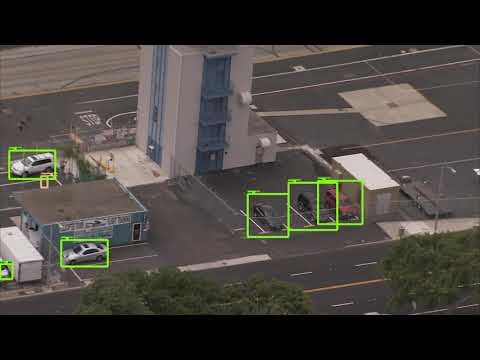
However, sometimes it tries to identify way too many objects:

On some video frames I noticed identification boxes blink switching object’s classes from person to cyclist, for example. Another misidentification I saw was a shoe being identified as a car. So while the model is pretty good at tracking, it makes classification mistakes as sometimes it tries really hard to identify objects. So what happens when I compare its performance to the faster but less accurate model 2?
Model 1

Model 2

From here we can see that even the “less intelligent” model 2 is doing really well. Maybe it can be a better model for the task at hand.
Model 1

Model 2

Unfortunately, it looks like this model 2 is good at identifying cars and other objects with predictable shapes, but not much else. So if we care about tracking a variety of objects from air, we still need to use model 1 which requires a strong hardware in order to run in real-time.
Future Improvements
In the future, I’d like to expand the scope of this project to better localize objects either via slanted boxes or objects’ silhouettes. I would also like to include objects’ velocities and predict their trajectories.
References
- “NSA Head: Surveillance Helped Thwart More Than 50 Terror Plots.” Washington Post. N. p., 2017. Web. 7 Sept. 2017.
- “Neovision2 Dataset - Ilab - University Of Southern California.” Ilab.usc.edu. N. p., 2017. Web. 8 Sept. 2017.